

The AI Agent Prompt Engineering Trap: Diminishing Returns and Real Solutions
Learn when prompt tweaks help and when architecture, data, and evaluation matter for production-ready AI systems.
Founders burn 40+ hours tweaking prompts when the real breakthrough requires a few hours of architectural work. Teams obsess over wording while their RAG retrieval returns garbage. Most rely on manual spot-checks, giving a false sense of confidence. Prompts become a scapegoat for systemic problems.
Prompt engineering is powerful early on, it can lift accuracy from 40% to 75% in hours. But beyond that, the gains come not from wordsmithing, but from better context, modular design, evaluation pipelines, and tooling.
This article helps you cut through the noise. You’ll get:
- A framework to know when prompt iteration actually pays off versus when it’s avoidance;
- A decision tree for choosing between prompt tweaks and architectural fixes;
- Clear guidance on what “good enough” looks like and when to stop chasing diminishing returns;
- Practical advice for MVP and post-MVP founders implementing AI features without wasting weeks on guesswork.
Why Measurement Gaps Create the Trap
Most teams skip building an evaluation framework entirely and "this version feels better" becomes the only metric. Manual testing on the same 3-5 examples creates false confidence about general performance.
Without measurement, confirmation bias takes over. Successful tweaks get remembered, failures get forgotten. Teams can't tell if they're at 60% or 85% accuracy, can't identify which specific cases improved, and can't separate random variation from actual progress.
Research supports this pattern:
Anthropic's prompt engineering guide stresses starting with clear success criteria and empirical evaluation before diving into prompt tweaks.
Hamel Husain, who led ML infrastructure at GitHub, observed that teams focusing only on prompt engineering “can’t improve their LLM products beyond a demo” — most failures come from weak evaluation systems, not bad prompts.Eugen Yan adds that a strong evaluation system is what separates teams rushing out low-quality models from those building serious, production-ready LLM products.
The measurement problem explains why smart teams get stuck: without data, it feels like progress, even when nothing is improving.
Signs You're Over-Engineering Prompts
Use these six red flags to recognise when iteration has stopped adding value and started wasting time.
Time versus improvement ratio breaks down. First 5 hours of prompt work: 35% improvement. Next 20 hours: 5% improvement. Next 40 hours: 1% improvement. The pattern becomes obvious in retrospect but feels invisible during execution.
Whack-a-mole failures appear. Fix the prompt for case A, case B breaks. Fix case B, case C starts failing. The model seems inconsistent, but the real issue is architectural – one prompt handling too many distinct scenarios.
Prompt length explodes. Started at 500 tokens. Now at several thousand or tens of thousands of tokens trying to cover edge cases through explicit instructions. New edge cases still break despite the bloat. This signals missing routing or decomposition, not insufficient prompt detail.
Superstitious optimisation emerges. Team debates "please" versus "you must" for an hour. Engineers reorder bullet points hoping for magic. Examples get added beyond 8-10 without measuring impact. Formatting changes happen without clear reasoning. These are symptoms of having exhausted legitimate prompt improvements.
"This version feels better" becomes the metric. No eval dataset, no comparison data, just vibes. Manual testing on the same 3-5 examples creates false confidence.
Team misalignment on quality. Engineers disagree on which prompt version is "better" with no objective way to resolve the disagreement. Prompt review sessions turn into endless bikeshedding. This indicates missing evaluation infrastructure, not a need for better prompts.
When Prompt Engineering Actually Matters
Prompt engineering delivers value when focused on high-leverage components. The 20% of work that drives 80% of results breaks down clearly.
High-Leverage Prompt Work
Clear role and task definition. "You are a customer support agent with access to order database" sets appropriate behavior and boundaries. One paragraph suffices – multiple pages of role description adds noise without improving understanding. This is one-time setup work with massive reliability gain.
Specific decision rules and guidelines. This is the most underrated high-leverage prompt component. Concrete criteria for what to look for and how to act eliminates most "model isn't understanding" problems.
Not vague instructions like "be helpful" or "use good judgment." Instead: numbered lists of specific signals, explicit decision criteria, edge case handling. What TO look for, what NOT to consider, how to choose between options.
Example structure: "Classification criteria: 1) [specific indicator], 2) [specific indicator]... 10) [specific indicator]. NOT this category: [clear exclusions]"
Spending time here once saves weeks of prompt iteration later.
Clear output formatting. Specify JSON schema, XML structure, or exact format expected. One-time setup, massive reliability gain. Models perform significantly better with explicit structure rather than inferring format from examples.
Few-shot examples (1-6 is usually enough). One-shot is often sufficient to establish structure and tone. Add more for nuanced scenarios that occur frequently enough to matter.
Typical sweet spot: 2-6 examples depending on output length and task complexity. Long outputs (500+ tokens each): 1-3 examples max – token budget matters. Short outputs or classifications: up to 10 if really needed (doubtfully), but usually 3-5 works.
Diminishing returns kick in fast. Adding another example beyond the first few rarely helps. Quality and diversity matter more than quantity.
Chain-of-thought for complex reasoning. "Think step by step before answering" works for multi-step tasks without requiring extensive tuning. This is another one-time setup that either helps or doesn't – iterating on CoT phrasing rarely improves results.
Low-Leverage Prompt Work
Wording perfectionism. "Use" versus "utilise," "please" versus "you must." Reordering bullet points. Adding adjectives and emphasis. These changes make prompts feel more polished without improving model behavior.
Endless example expansion. Adding the 11th, 12th, 15th, 20th example without measuring impact. Examples that are variations of existing ones rather than covering new patterns. Past 5-10 good examples, more examples add token cost without improving accuracy.
Defensive prompt bloat. Adding edge case handling to main prompt: "If user asks X, do Y. If user asks Z, do W..." This should be handled by routing and architecture, not prompt instructions. These additions make prompts longer without making them better.
Prompt archaeology. "Let's try the version from 2 weeks ago" without a hypothesis about why it would work better. No measurement of past versions to know which actually performed best. This is guesswork disguised as engineering.
The "Good Enough" Checklist
At this point, you might be wondering how do you know when your prompt is good enough to stop editing and move on?now when your prompt is good enough? Pay attention to the following points, if these are in place, it’s time to stop tweaking and start testing:

If you have these and accuracy is still below 85%, the problem is NOT the prompt.
The Decision Framework
Not sure whether to keep editing your prompt or rethink your system? Follow this framework to find out where the real problem lies.
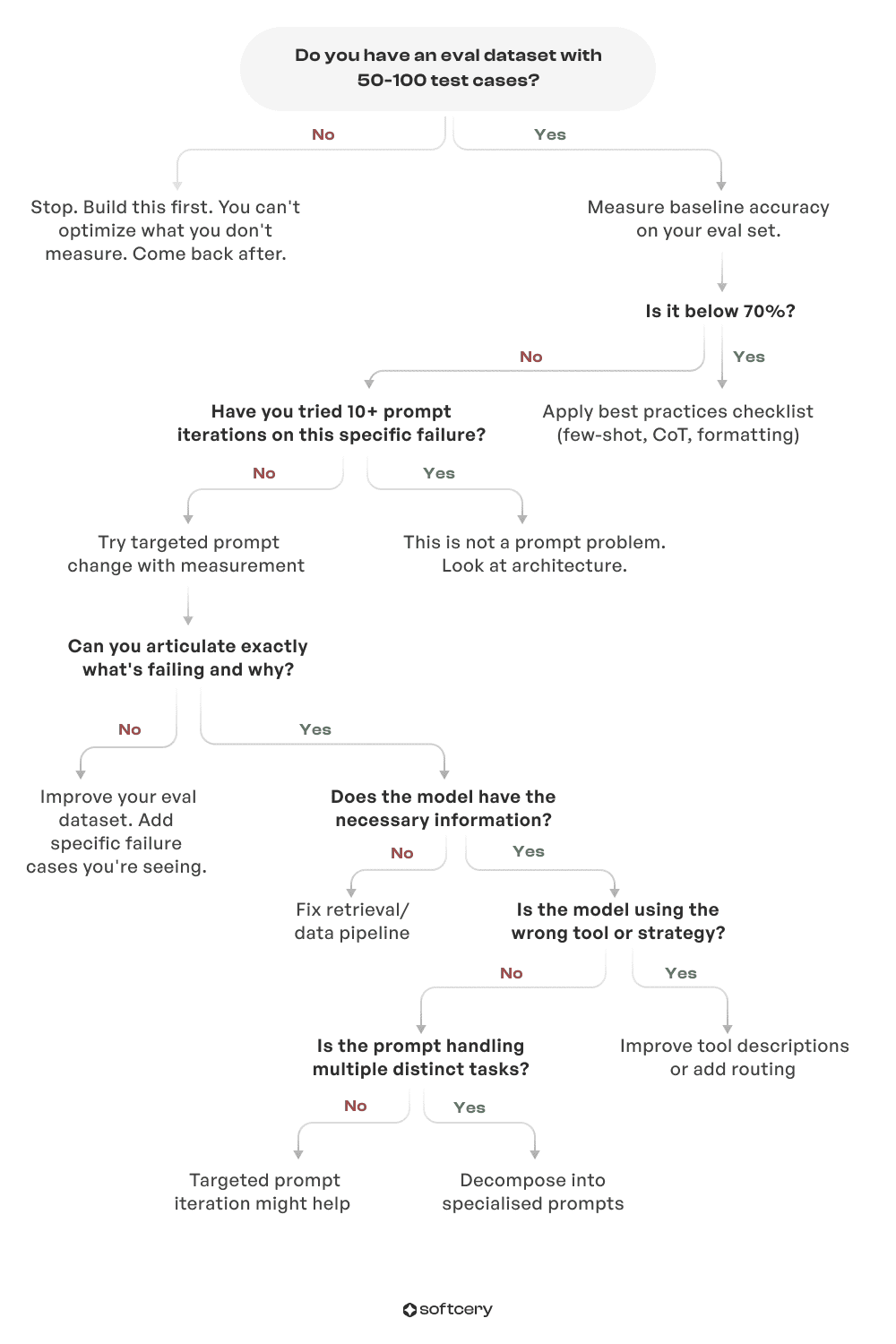
Case Study: E-Commerce Support Agent
Weeks 1-3: Team manually tests prompts on a handful of examples. "This version handles returns better." "Let's add more examples for order status." 80+ iterations based on gut feel. No measurement of actual performance.
Week 4: Finally built an eval dataset with 100 real customer queries. Measured baseline: 62% accuracy. Shocking – team thought they were at 80%+ based on manual testing.
Applied prompt best practices: 71% accuracy (9-point jump). 10 more targeted iterations: 74% accuracy (3-point jump). Plateau hit.
Root cause discovered through eval analysis: Monolithic prompt handling order status, returns, product questions, and complaints. The prompt tried to be good at everything, excelling at nothing. No amount of wording refinement could fix this architectural problem.
Solution: Decomposed into 4 specialised agents, each with simple prompts. Router classifies intent, routes to specialised agent. Each specialist handles one scenario well, 90% accuracy within days is a result.
What to Do Instead
When prompt iteration stalls, five architectural fixes deliver more value than continued refinement.
Decomposition
Poor decomposition is one of the most popular reasons why AI agent prototypes fail in production. Monolithic prompt handling 10+ different intents should route to specialised prompts. One agent doing everything should become specialised agents per task.
Example: Instead of one "customer support agent" prompt, route to "order status agent," "returns agent," "product questions agent." Each specialist prompt can be simpler and more reliable than the monolithic version.
Context Quality
Garbage in, garbage out applies to context more than prompts. A mediocre prompt with clean, structured, relevant context outperforms a perfect prompt with messy context.
Common context problems that no amount of prompt tuning can fix:
Huge unstructured data dumps. Model gets lost in noise. Retrieval returns entire documents instead of relevant sections. Everything looks equally important, so nothing stands out.
Irrelevant information mixed with relevant. Signal gets diluted. The model wastes reasoning on irrelevant details. Context window fills with noise instead of useful information.
Missing preprocessing and formatting. Raw data versus structured data. Unformatted text versus clearly labeled sections. Models perform significantly better with structure.
No clear hierarchy or organisation. Everything appears at the same priority level. The model can't identify what matters most. Key information gets buried in less important details.
The fix: Dynamic context building with preprocessing
Filter: only include information relevant to the specific query. Structure: organise context with clear sections, labels, metadata. Clean: remove noise, duplicates, formatting artifacts. Prioritise: put most relevant information first.
Example: Instead of dumping an entire document, extract relevant sections, format clearly, add metadata indicating importance. This is architectural work, not prompt work, but has bigger impact than any prompt refinement.
Data Quality and Retrieval
Reliable results come from production-ready agentic RAG systems, not more prompt tuning. If retrieval returns the wrong documents or context is low quality, no amount of prompting can fix it.
Tooling Improvements
Vague function names/descriptions → clarify (this IS prompt work worth doing). Missing tools → add capabilities instead of prompting model to compensate. Poor tool response formats → structure outputs properly.
Tool descriptions deserve the same attention as main prompts – they're often more important. Many teams spend 40 hours optimising their agent prompt while leaving tool descriptions at "search - searches for stuff."
Model Selection
Wrong AI agent LLM selection for the task complexity means no amount of prompting will fix the ceiling. Cheaper/faster model can't handle reasoning required – upgrading the model delivers more than 100 prompt iterations.
Evaluation Framework (Foundational)
Build an eval dataset with 50–100 real cases. Measure accuracy per failure mode and track which prompt changes fix which cases. Strong AI agent observability reveals which problems are prompt-fixable versus architectural, it shows exactly when iteration stops helping and makes the gains curve visible instead of invisible.
How Much Time to Spend on Prompts
Concrete time allocation prevents endless iteration.
Initial setup (one-time, 5-10 hours total): Follow the "Good Enough" checklist. Most time goes to decision rules (2-3 hours) and examples (1-2 hours). Everything else is quick setup.
Optimisation phase (2-4 hours):
Maintenance (ongoing, less than hour/week):
Spending 20+ hours per week on prompt tuning for the same agent means being trapped in diminishing returns.
Better allocation:
This allocation recognises that prompts matter but are one component in a larger system. Most reliability improvements come from architecture, not wording.
Real Life Examples
At Softcery, we see these patterns repeatedly when helping teams move from prototypes to production. The breakthroughs consistently come from architecture, not wording.
The tool description fix: Legal document analyzer spent 3 weeks optimizing main prompt, stuck at 80%. Root cause: Vague function names (search_docs, get_info). Model didn't know when to use which tool.
Solution: 2 hours rewriting tool descriptions with clear parameters and examples. 88% accuracy immediately. Lesson: Tool descriptions are prompts – often more important than main prompt.
The eval-first approach: Customer intent classifier built eval dataset of 100 real customer messages first. Measured baseline: 72% accuracy. Applied best practices: 81% accuracy (9-point jump). 5 targeted iterations: 85% accuracy (4-point jump).
Analysis showed remaining failures were ambiguous even for humans. Stopped prompt work at 85%, focused on confidence thresholds and human handoff. Shipped in 10 days instead of iterating for months.
The decomposition win: Marketing content generator had single prompt handling blog posts, social media, emails, ad copy. Each format needed different tone, length, structure. Massive prompt trying to cover all cases.
Solution: Separate prompt per content type, shared core brand voice guidelines. Each specialized prompt was 1/4 the length, 2x more reliable.
These examples share a pattern: the breakthrough came from architectural changes, not prompt refinement. Teams tried extensive iteration first, wasting weeks, before addressing the real issue.
The Path Forward
Prompt engineering is real and important – for the first 70% of accuracy. Past that point, reliability comes from architecture, data, tooling, and measurement.
The trap is thinking prompts are the only solution. It's rational to fall into – early prompt work delivers such obvious gains that continuing feels logical. But the gains curve flattens predictably. Recognizing the plateau requires measurement, not intuition.
"Good enough" is well-defined: clear role, specific guidelines, explicit format, a few good examples, appropriate CoT, solid tool descriptions. If you have these and accuracy still lags, the problem lives elsewhere.
The 10-iteration rule provides a clear stopping point. If ten focused attempts at rephrasing don't fix a specific failure mode, the issue is architectural. Time to decompose, clean context, improve tooling, select better models, or build evaluation infrastructure.
This framework transforms prompt work from endless iteration into bounded effort. It separates high-leverage initial work from low-leverage perfectionism. It defines when to stop prompt tuning and pivot to architectural fixes.
Frequently Asked Questions
How do I know if I'm spending too much time on prompt engineering?
Track time versus improvement ratio. If 20+ hours per week go to prompt tuning for the same agent, that's a red flag. If 40 hours of iteration yields less than 5% accuracy improvement, stop. The pattern: first 5 hours deliver 35% gains, next 20 hours deliver 5%, next 40 hours deliver 1%. When the ratio breaks down, the problem is architectural, not linguistic.
When should I stop iterating on prompts and focus on architecture instead?
Apply the 10-iteration rule: if 10 focused prompt iterations don't fix a specific failure mode, stop. The issue is architectural. Also stop when accuracy plateaus below 85% despite having the "good enough" checklist components (clear role, decision rules, format, 1-6 examples, CoT, tool descriptions). If you have these and performance still lags, no amount of wording refinement will close the gap.
What's the minimum "good enough" prompt structure?
Six components: clear role and task definition (one paragraph), specific decision rules with numbered criteria, explicit output format with schema, 1-6 few-shot examples covering main patterns, chain-of-thought instruction if reasoning is complex, and clear tool/function descriptions. If you have these and accuracy is below 85%, the problem is not the prompt.
When does fine-tuning make more sense than prompt engineering?
Almost never. Modern models handle nearly every task with proper architecture and prompt engineering. Fine-tuning requires very high-quality datasets (100k+ examples), significant resources, and multiple attempts to get right. Teams rarely succeed on the first try. The cases where it makes sense are extremely rare: highly specialized domain language that no base model understands, strict formatting requirements across millions of outputs where prompt compliance isn't sufficient, or cost optimization at massive scale (millions of requests per day) where shorter prompts justify the investment. Even then, fix architecture, decomposition, and context quality first, and you'll most certainly find you never needed fine-tuning in the first place.
How many few-shot examples should I include?
Start with 1-2 examples. One-shot is often sufficient to establish structure and tone. Add more only for nuanced scenarios that occur frequently enough to matter. Typical sweet spot: 2-6 examples depending on output length and task complexity. Long outputs (500+ tokens): 1-3 examples max. Short outputs: up to 10 if really needed, but usually 3-5 works. Diminishing returns kick in fast, adding example #7+ rarely helps.


